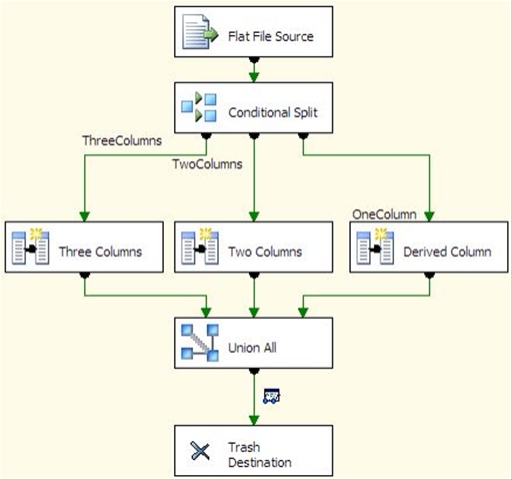
A question was posted on the MSDN forums about validating that there are no overlapping rows in a slowly changing dimension (SCD). It is common to use a start and end date in a type 2 SCD to designate when each version of the dimension member was in effect. However, it can create problems if the date ranges for one version of the row overlap with other versions of the row.
A simple way to validate that there is no overlap in an existing dimension table is to run the following query:
SELECT
*
FROM
DimTable A
LEFT JOIN DimTable B ON (A.BusinessKey = B.BusinessKey AND A.DimID <> B.DimID)
WHERE
(A.BeginDate BETWEEN B.BeginDate AND B.EndDate
OR A.EndDate BETWEEN B.BeginDate AND B.EndDate)
ORDER BY
A.DimID
It simply joins the table to itself to compare the date range of a given row with other rows that have the same business key. It assumes that the dimension table contains a surrogate key, a business key, and a begin and end date.
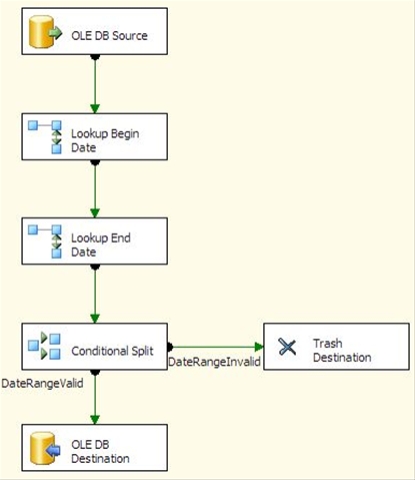
That’s great if you are validating the table after the fact, but what if you want check a new row before you insert it? In some cases, especially if you are dealing with dimension rows that arrive out of sequence, you may need to validate that the effective range for a new row doesn’t overlap with existing rows. If you want to do this in a data flow, the method above doesn’t work, nor does it lend itself to a simple Lookup. You’d need to perform a BETWEEN in the Lookup, which means that caching needs to be disabled. On large lookup tables, this can result in poor performance.
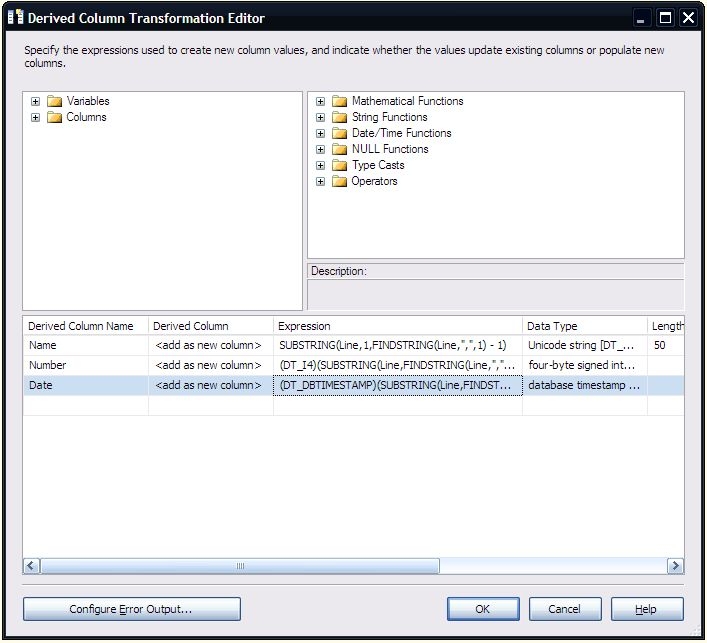
What is really needed is a way to perform an equi-join between the business key and each of the effective dates, so that we can use the caching mode of the Lookup. Fortunately we can do this in SQL Server 2005 using a recursive common table expression (CTE). Using the CTE, we can generate a row for each “covered” date, that is, each day between the start and end effective dates. Once we have that, we can perform one lookup to match on the business key and begin date, and a second lookup to match on the business key and end date. If either of the lookups hits a match, then the date range for the new row overlaps an existing row.
This is the SQL for the lookups:
WITH DIM_CTE (
DimID
,BusinessKey
,CoveredDate
,BeginDate
,EndDate
,Days) AS
(
SELECT
dim.DimID
,dim.BusinessKey
,dim.BeginDate AS CoveredDate
,dim.BeginDate
,dim.EndDate
,1 AS Days
FROM
DimTable dim
UNION ALL
SELECT
dim.DimID
,dim.BusinessKey
,DATEADD(day, DIM_CTE.Days, dim.BeginDate) AS CoveredDate
,dim.BeginDate
,dim.EndDate
,DIM_CTE.Days + 1 AS Days
FROM
DIM_CTE INNER JOIN DimTable dim
ON (DIM_CTE.DimID = dim.DimID)
WHERE
DIM_CTE.Days <= DATEDIFF(day, dim.BeginDate, dim.EndDate)
)
SELECT
A.DimID, A.CoveredDate, A.BusinessKey
FROM
DIM_CTE A
OPTION (MAXRECURSION 400)
An important thing to note about the CTE is the use of the OPTION (MAXRECURSION 400). This is a query hint that tells SQL Server how many levels of recursion to allow. Since the CTE recurses once for each day between the effective start date and end date for the rows in the dimension table, you need to make sure that MAXRECURSION is set to the max days between start and end dates. You can use the following SQL to determine what value to use:
SELECT
MAX(DATEDIFF(day, dim.BeginDate, dim.EndDate))
FROM
DimTable dim
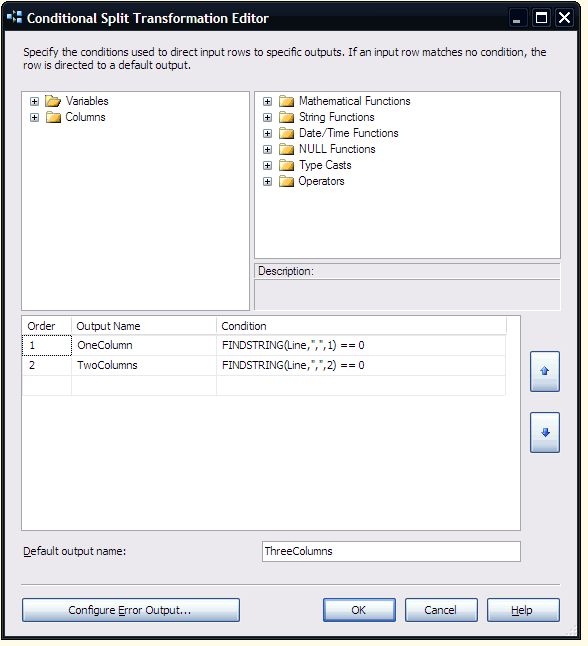
The Lookups in the SSIS package are both set to ignore failures. A conditional split is used to determine whether both dates fall outside a valid range (by checking whether an ID column was populated by the Lookup using this expression: “!(ISNULL(BeginDateID) && ISNULL(EndDateID))”.
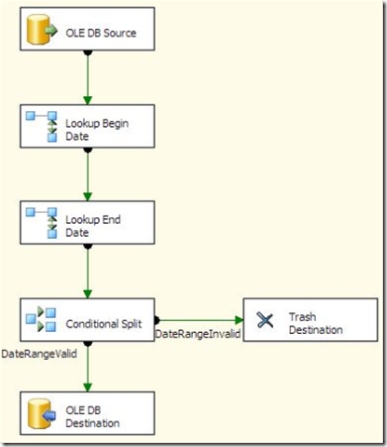
A caveat about this technique: the CTE can generate a lot of rows, which can impact performance. Depending on your scenario, it may make more sense to insert the rows, then perform a cleanup routine afterward, or to validate the date ranges in a batch operation before starting the data flow.
If you have any comments about optimizing or improving this, please leave a comment.