I often hear comments along the lines of “Why doesn’t SSIS have an XML destination?”. Unfortunately, I don’t know the answer to that, but I can show you how to implement your own XML destination fairly easily. Thanks to the magic of the script component, it doesn’t take much work at all. This was also a good opportunity for me to use a destination script component, as I haven’t had much need for this in my work.
One caveat to this is that I have kept the XML format very simple and very generic. You can customize the script to handle more complex scenarios, but I’d imagine there would be a lot of work in producing a component that can handle all the different ways of formatting data in XML. Maybe that’s why MS didn’t include it out of the box 🙂
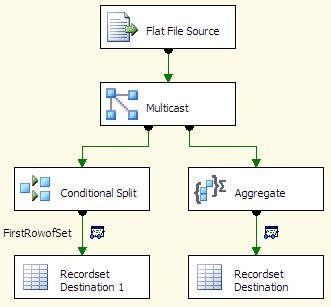
As an example, I have a very simple package with a single data flow. The data flow has a flat file source, and a script destination component.

The flat file source is standard, nothing interesting there. The work is all done in the script. When adding the script component, make sure to specify that it is a destination component.
When configuring the script component destination, I chose all the input columns that I wanted to include in the XML (in this case, all of the columns from my flat file).
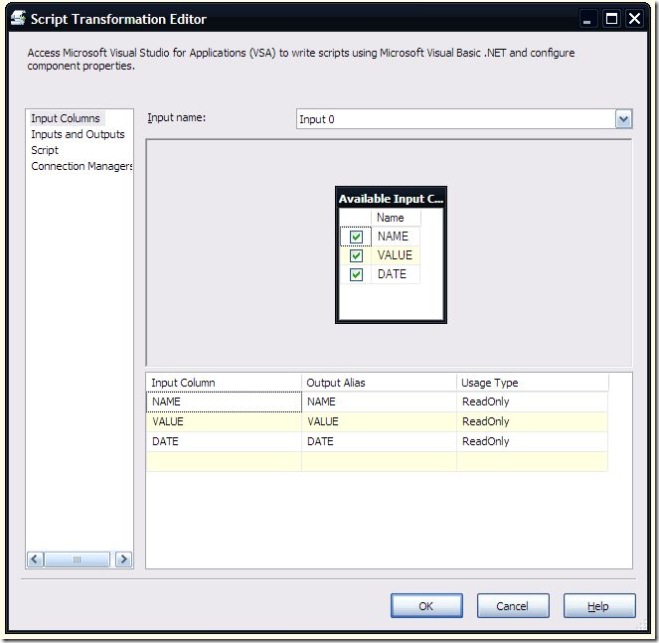
There is no need to alter anything on the Inputs and Outputs page. Since this is a destination component, no output is necessary. On the Connection Managers page, I added a reference to a connection manager of type “File”, and named it Destination.
This is the complete script for the component. I’ll explain it section by section below.
Imports System
Imports System.Data
Imports System.Math
Imports Microsoft.SqlServer.Dts.Pipeline.Wrapper
Imports Microsoft.SqlServer.Dts.Runtime.Wrapper
Imports System.IO
Imports System.Reflection
Public Class ScriptMain
Inherits UserComponent
Private targetFile As String
Private xmlWriter As StreamWriter
Private rootElement As String = “Root”
Private rowElement As String = “Row”
Public Overrides Sub AcquireConnections(ByVal Transaction As Object)
targetFile = CType(Me.Connections.Destination.AcquireConnection(Nothing), String)
End Sub
Public Overrides Sub PreExecute()
xmlWriter = New StreamWriter(targetFile, False)
xmlWriter.WriteLine(FormatElement(rootElement))
End Sub
Public Overrides Sub PostExecute()
xmlWriter.WriteLine(FormatElement(rootElement, True))
xmlWriter.Close()
End Sub
Public Overrides Sub Input0_ProcessInputRow(ByVal Row As Input0Buffer)
Dim column As IDTSInputColumn90
Dim rowType As Type = Row.GetType()
Dim columnValue As PropertyInfo
With xmlWriter
.Write(FormatElement(rowElement))
For Each column In Me.ComponentMetaData.InputCollection(0).InputColumnCollection
columnValue = rowType.GetProperty(column.Name)
.Write(FormatElement(column.Name) + columnValue.GetValue(Row, Nothing).ToString() + FormatElement(column.Name, True))
Next
.WriteLine(FormatElement(rowElement, True))
End With
End Sub
Private Function FormatElement(ByVal elementName As String) As String
Return FormatElement(elementName, False)
End Function
Private Function FormatElement(ByVal elementName As String, ByVal closingTag As Boolean) As String
Dim returnValue As String
If closingTag Then
returnValue = “</”
Else
returnValue = “<“
End If
returnValue += elementName + “>”
Return returnValue
End Function
End Class
I added the System.IO and System.Reflection to the Imports as I am using objects from both namespaces. There are 4 class level variables defined:
Private targetFile As String
Private xmlWriter As StreamWriter
Private rootElement As String = “Root”
Private rowElement As String = “Row”
xmlWriter is a StreamWriter, the .NET Framework object used to create the XML file. For more information on this, please see the MSDN documentation. rootElement is the value to enclose the entire XML document with, and rowElement defines what to enclose each individual row in. By changing the values in these variables, you affect what the final XML output looks like.
targetFile holds the path and file name for the destination file. It is set in the AcquireConnections method. Interesting note: when you are working with a file connection manager, calling AcquireConnection simply returns the path and file name of the file. Why not just use a variable or set it explicitly? Doing it this way makes the script behave more like a standard SSIS destination, and makes it clearer what you’d need to change to put the file in a new destination. As a plus, if you set an expression or configuration on the ConnectionString property of the file connection manager, the script will use it automatically.
Public Overrides Sub AcquireConnections(ByVal Transaction As Object)
targetFile = CType(Me.Connections.Destination.AcquireConnection(Nothing), String)
End Sub
In the PreExecute method, the code creates a new instance of the StreamWriter, and writes the opening tag of the XML file.
Public Overrides Sub PreExecute()
xmlWriter = New StreamWriter(targetFile, False)
xmlWriter.WriteLine(FormatElement(rootElement))
End Sub
The ProcessInputRow method is where most of the work occurs. I’m using the System.Reflection and the ComponentMetaData objects to process the Row object dynamically. Essentially, this code determines what input columns are available at runtime, based on what was selected in the Script component’s property pages. It then writes each of those columns to the file, surrounding it with an XML tag based on the column name.
Public Overrides Sub Input0_ProcessInputRow(ByVal Row As Input0Buffer)
Dim column As IDTSInputColumn90
Dim rowType As Type = Row.GetType()
Dim columnValue As PropertyInfo
With xmlWriter
.Write(FormatElement(rowElement))
For Each column In Me.ComponentMetaData.InputCollection(0).InputColumnCollection
columnValue = rowType.GetProperty(column.Name)
.Write(FormatElement(column.Name) + columnValue.GetValue(Row, Nothing).ToString() + FormatElement(column.Name, True))
Next
.WriteLine(FormatElement(rowElement, True))
End With
End Sub
Finally, in the PostExecute method, the closing tag is written, and the file is closed.
Public Overrides Sub PostExecute()
xmlWriter.WriteLine(FormatElement(rootElement, True))
xmlWriter.Close()
End Sub
With the script component in place, if I read in a text file with these values:
NAME;VALUE;DATE
A;1;1/1/2000
A;2;1/2/2000
A;3;1/3/2000
A;4;1/4/2000
A;5;1/5/2000
I get an output that looks like this:
<Root>
<Row><NAME>A</NAME><VALUE>1</VALUE><DATE>1/1/2000 12:00:00 AM</DATE></Row>
<Row><NAME>A</NAME><VALUE>2</VALUE><DATE>1/2/2000 12:00:00 AM</DATE></Row>
<Row><NAME>A</NAME><VALUE>3</VALUE><DATE>1/3/2000 12:00:00 AM</DATE></Row>
<Row><NAME>A</NAME><VALUE>4</VALUE><DATE>1/4/2000 12:00:00 AM</DATE></Row>
<Row><NAME>A</NAME><VALUE>5</VALUE><DATE>1/5/2000 12:00:00 AM</DATE></Row>
</Root>
The nicest thing about this script, in my opinion, is that it does not have to be modified if the input columns change. The use of the System.Reflection classes allows the code to process the Row object at runtime. This does come at the expense of performance, though, so I wouldn’t recommend using this in high volume scenarios without some tweaks.