
A recent post on the MSDN forums brought up an interesting problem. The poster was attempting to process a folder of files, all of which had the same format, but some were encoded as ASCII (ANSI, DT_STR, or varchar, if you like the SQL Server data types) and some were encoded as Unicode (DT_WSTR, nvarchar).
The initial issue was determining which way the file was encoded. After a little research, I located a post entitled “Detecting File Encodings in .NET” by Heath Stewart. This showed how to check the encoding of a file in C#. I converted the code to VB.NET and set it up to work within a Script Task. These are the results:
Public Sub Main()
”’Code based on sample originally posted here: http://www.devhood.com/tutorials/tutorial_details.aspx?tutorial_id=469
Dim file As System.IO.FileStream = Nothing
Dim isUnicode As Boolean = FalseTry
file = New System.IO.FileStream(Dts.Connections(“TestFileAnsi”).AcquireConnection(Nothing).ToString(), _
System.IO.FileMode.Open, System.IO.FileAccess.Read, System.IO.FileShare.Read)
If file.CanSeek Then
Dim bom(4) As Byte ‘ = Byte ‘// Get the byte-order mark, if there is one
file.Read(bom, 0, 4)
If ((bom(0) = &HEF And bom(1) = &HBB And bom(2) = &HBF) Or _
(bom(0) = &HFF And bom(1) = &HFE) Or _
(bom(0) = &HFE And bom(1) = &HFF) Or _
(bom(0) = 0 And bom(1) = 0 And bom(2) = &HFE And bom(3) = &HFF)) Then
isUnicode = True
Else
isUnicode = False
End If
‘// Now reposition the file cursor back to the start of the file
file.Seek(0, System.IO.SeekOrigin.Begin)
Else
‘// The file cannot be randomly accessed, so you need to decide what to set the default to
‘// based on the data provided. If you’re expecting data from a lot of older applications,
‘// default your encoding to Encoding.ASCII. If you’re expecting data from a lot of newer
‘// applications, default your encoding to Encoding.Unicode. Also, since binary files are
‘// single byte-based, so you will want to use Encoding.ASCII, even though you’ll probably
‘// never need to use the encoding then since the Encoding classes are really meant to get
‘// strings from the byte array that is the file.
isUnicode = False
End IfDts.TaskResult = Dts.Results.Success
Catch e As Exception
Dts.TaskResult = Dts.Results.Failure
Finally
If Not file Is Nothing Then
file.Close()
End IfTry
Dim vars As Variables
Dts.VariableDispenser.LockOneForWrite(“isUnicode”, vars)
vars(“isUnicode”).Value = isUnicode
vars.Unlock()
Catch ex As Exception
Dts.TaskResult = Dts.Results.Failure
End Try
End Try
End Sub
Essentially, the script above is getting the file path from a flat file connection manager. It’s then checking the byte order mark (BOM), which is what tells us if the file is Unicode or not. The script assumes that the file is ASCII, if it can’t determine it from the BOM. The result of the check is written to a boolean variable defined in the package called isUnicode.
That part was relatively straightforward. Originally, I thought I could just use this variable to set the Unicode property on the flat file connection manager through an expression, and use the same dataflow, as long as I typed all the string columns as DT_WSTR (I really should have known better). Oddly enough, when I first tested this, I found that if I set the Unicode property to false on the connection manager, but set the column types to DT_WSTR, I could process ASCII files without a problem, but Unicode files didn’t send any rows through, even though there was no error. If I set the Unicode property to true, and then set it to false via an expression, the flat file source threw a validation error because the error output was using a DT_NTEXT type, and it needs to use DT_TEXT with ASCII files.
What I ended up with instead isn’t quite as simple, but it does work consistently. I created two connection managers, one configured for ASCII, and the other for Unicode. Both connection managers have an expression defined that sets their ConnectionString property based on the same variable, so they both point at the same file. Then I created two data flows, one for ASCII, one for Unicode. This eliminates any metadata errors. Finally, I set precedence constraints from the script task to each data flow, and made execution conditional based on the isUnicode variable.

The constraint to DF ANSI looks like this: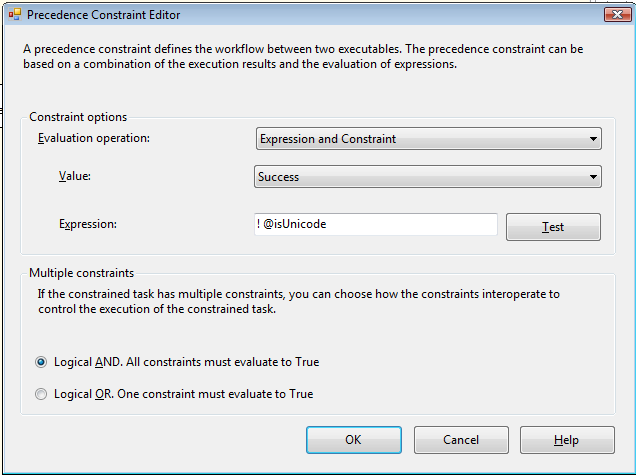
and the constraint to DF Unicode looks like: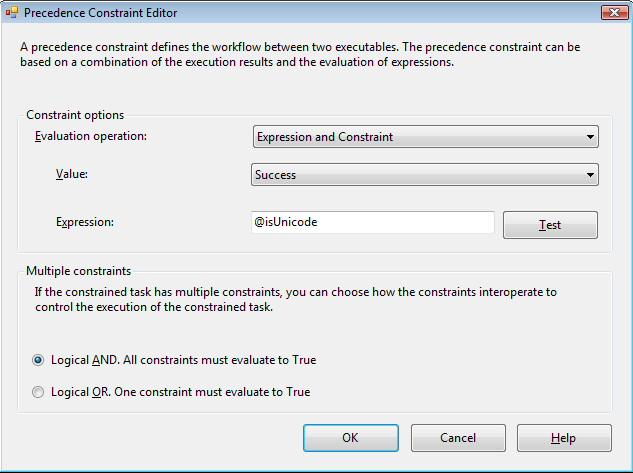
The sample files for this (included a text file formatted as Unicode and ASCII) are on my Live Drive:

To switch the test file from ASCII to Unicode, change the file path in the “testFilePath” variable.