
In my previous post, I discussed how to use a script destination to output multiple flat files from a single source. In it, I mentioned that I would post an alternate approach, that didn’t require any scripting. So, here it is.
This is using the same example data as the previous post, a source file that looks like:
NAME;VALUE;DATE
A;1;1/1/2000
A;2;1/2/2000
A;3;1/3/2000
A;4;1/4/2000
A;5;1/5/2000
B;1;1/1/2000
B;2;1/2/2000
B;3;1/3/2000
B;4;1/4/2000
B;5;1/5/2000
C;1;1/1/2000
C;2;1/2/2000
C;3;1/3/2000
C;4;1/4/2000
C;5;1/5/2000
The goal is to output one file containing all “A” rows, one with “B” rows, and one with “C” rows.
The control flow consists of a Data Flow, ForEach container, and another Data Flow.
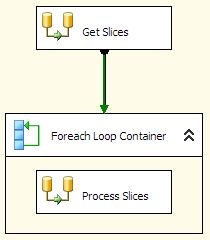
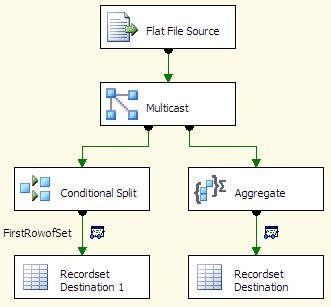
The first data flow is used to get the number of “slices” in the original file, and the data to identify each slice. The results are stored in a recordset object that is used by the ForEach loop. In the recordset, I expect to see three records, with the values A, B, and C. To get that from the source, I can either use a conditional split, or an aggregate transform. Important: you do not need both; I am only including both approaches as examples. If you implement this as a real solution, please only use the approach that best suits your needs.
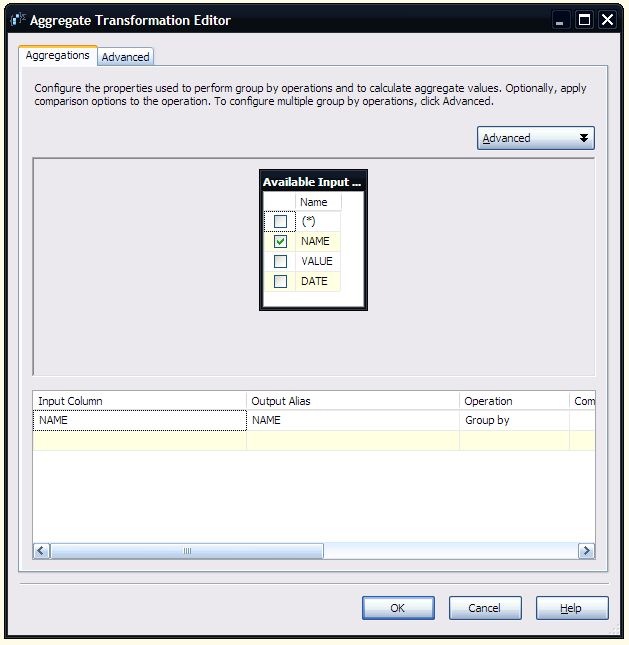
The aggregate transform is set to group by and pass through the Name column from the source file.
The condition split works by looking for rows with a value of 1. Those are the only rows passed to the recordset destination.

The choice of which one to use really depends on how complex the rules for determining how many files you need are. If it is based on a single column, or set of columns, the aggregate transform works well. For more complex logic, the conditional split is probably more appropriate.
Once the recordset is populated, it is stored in a variable. There are two defined, one to hold the results of the conditional split (splitRowList), and one to hold the results of the aggregate transform (aggregatedRowList). Again, you don’t need both. The aggregatedRowList is the one used for the rest of this example.

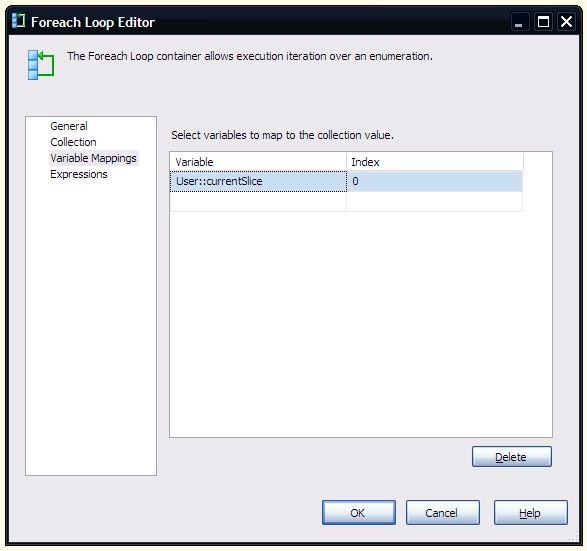
The Foreach loop is set to use the aggregatedRowList variable.
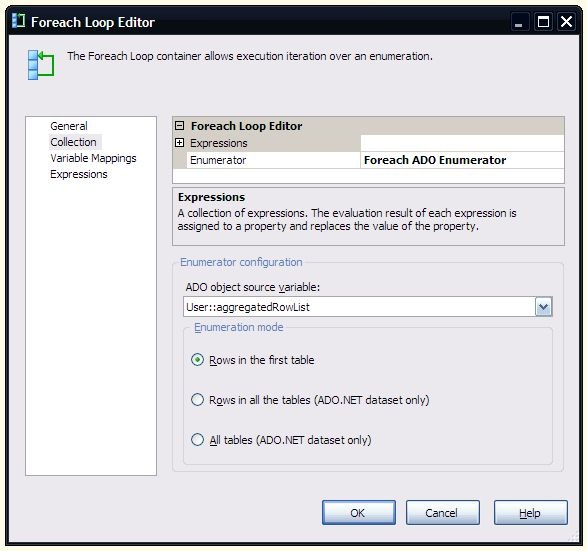
The first column of the recordset (the Name column) is mapped to the currentSlice variable. This is what is used in the data flow to determine whether the row should be included in the output. It is also used in an expression for the currentFile variable, which is also used to set the ConnectionString property of the Destination File connection manager:
“C:\OutputDir\” + “Output” + @[User::currentSlice] + “.txt”
This updates the destination filename for each iteration of the loop.
In the data flow, the source and destination are fairly straightforward.

In the conditional split, the currentSlice variable is compared to the Name column to determine if this row should be included in the output. More complex logic could be included here fairly easily.

That’s pretty much all there is to it.
Why would you want to use this approach over using a script? For one, this would be easy to adapt to multiple table destinations, instead of flat files. Two, this approach does not care about whether the rows are sorted or not. However, it is reliant on the conditional split, so the logic for which output a row belongs in needs to be something that can be implemented in a conditional split. And it does require multiple passes through the source rows. The script approach seems to be better suited to sequential, single pass file processing.