
In Handling Flat Files with Varying Numbers of Columns, I showed an example of parsing a flat file with an inconsistent number of columns. I used a script component, but Jamie commented that the same thing could be accomplished through a Conditional Split and Derived Column transform. So, here’s part 2.
I added a new data flow to the same package. The data flow is a bit more complicated for this.
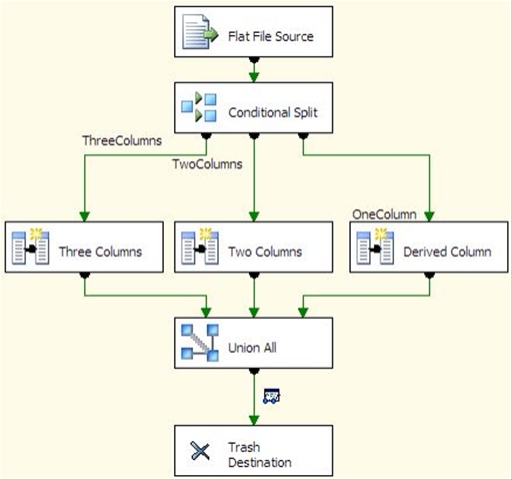
The Conditional Split determines what type of row I’m dealing with, and passes it to the appropriate output. It does this by checking how many delimiters appear in the row. The FindString function will return a 0 if the string specified is not found, or if the string specified occurs less than the number of occurrences specified.
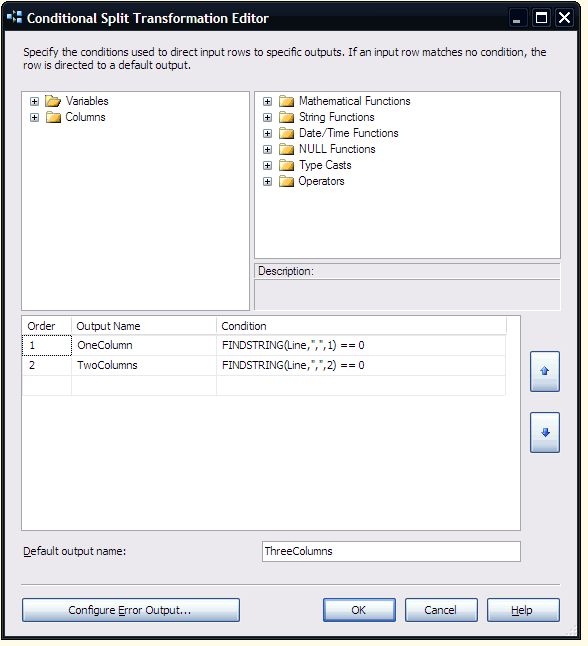
Now that I know how many columns I need to parse, I’m use a Derived Column transform to split the columns from the main string.
The expression for the first column looks for the first occurrence of the delimiter.
SUBSTRING(Line,1,FINDSTRING(Line,”,”,1) – 1)
For the second column, the expression is a bit more complicated. It has start from the first delimiter, and stop at the second. Since the SubString function needs the length, the expression is calculating the difference between the first and second delimiter. In addition, it is casting the result to an integer.
(DT_I4)(SUBSTRING(Line,FINDSTRING(Line,”,”,1) + 1,FINDSTRING(Line,”,”,2) – FINDSTRING(Line,”,”,1) – 1))
Finally, the third expression finds the second delimiter, and gets the rest of the string. I’m taking a shortcut by using the full value for the length, since if the length argument is exceeds the length of the string, the rest of the string is returned.
(DT_DBTIMESTAMP)(SUBSTRING(Line,FINDSTRING(Line,”,”,2) + 1,LEN(Line)))
Finally, a Union All is used to combine the data back into a single flow.
Technically, this could be accomplished without the Conditional Split. However, the logic required for the Derived Column transform would be much more complex, as each column parsing expression would have to be wrapped in a conditional expression to see if that column actually existed for the row.
In SSIS, there are usually at least two ways to accomplish anything, which is one of the things I like about it. However, there are differing advantages to the two approaches covered here and in the previous post. In general, I favor using the script component for the following reasons:
- Easier (at least in my opinion) to introduce complex logic for parsing the columns
- Simpler data flow
However, the Derived Column is easier if you aren’t comfortable with .NET coding, and makes it easier to interpret what is happening in the data flow.
I’ve attached the updated sample package at the end of this post.