
A question came up recently on the SSIS forums on translating lookup codes into a description within the data flow. That is, given code “A”, how do you translate it into a more descriptive value, such as “Apple”?
As a general rule of thumb, if the the codes and values might change over time, or if there are a significant amount of them, I would store them in a database table, and use the Lookup component to handle the translation. This makes maintenance much easier, and Lookup components have great performance. In fact, I do this in most cases, since even things that aren’t supposed to change have a habit of doing so.
The question posed on the forum was for a small set of 4 translations. In this case, assuming these values were not going to change often or at all, the suggestions were to use one of three methods: the script component, the derived column component, or the lookup component with a hard-coded list of values (suggested by Phil Brammer http://www.ssistalk.com).
I decided to run each method through its paces to determine how each one performs. I was fairly confident that the script component would be slower than the other options, but I was less sure about the lookup and derived column. So I set up a test package for each scenario, and ran some rows through them to see how they did.
I’ve got the testing methodology below this if you’re interested, but I’m going to jump right into the results. I ran each package 5 times for 500,000 rows and another 5 times for 1,000,000 rows. The lookup performed the best in each test, and the script performed the worst. The derived column transform came close to the lookup and actually beat the lookup once when running the million row test, but the lookup still come out ahead based on the overall average. We are talking about a couple of seconds over a million rows, but every little bit helps.
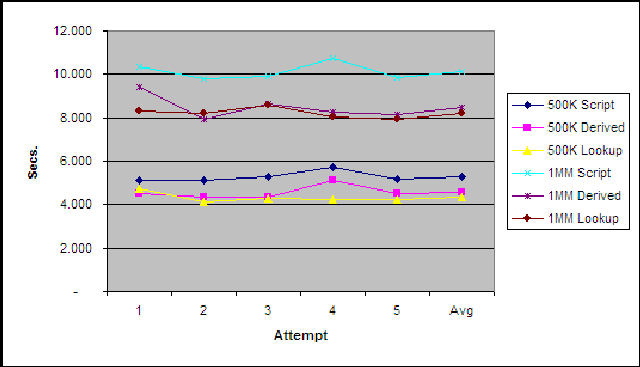
So, it looks safe to continue using the lookup transform for any type of translation, even when the values are hard-coded.
Scenarios for Testing
Each package has a single data flow in it. The script package has the following in the data flow:
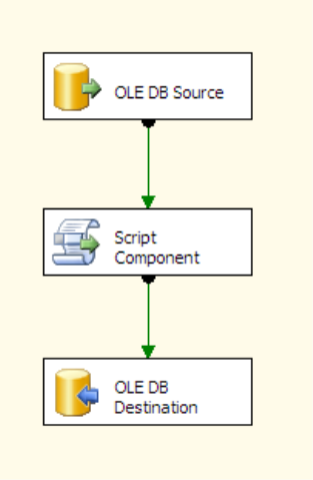
and has this code in it:
Select Case Row.LOOKUPVALUE
Case “A”
Row.Description =
“APPLE”Case “B”
Row.Description =
“BANANA”Case “C”
Row.Description =
“CANTALOUPE”Case “D”
Row.Description =
“DATE”Case “E”
Row.Description =
“EGGPLANT”Case Else
Row.Description =
“UNKNOWN”End Select
The derived column flow looks like:
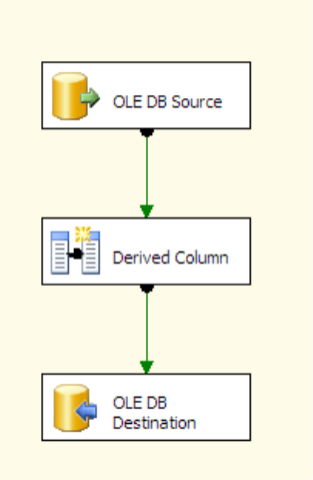
The derived column is using this code:
LOOKUP_VALUE == “A” ? “APPLE” : LOOKUP_VALUE == “B” ? “BANANA” : LOOKUP_VALUE == “C” ? “CANTALOUPE” : LOOKUP_VALUE == “D” ? “DATE” : LOOKUP_VALUE == “E” ? “EGGPLANT” : “UNKNOWN”
The lookup looks like:
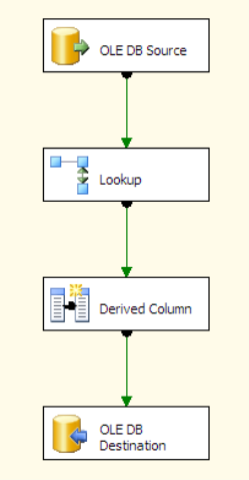
and uses this to generate the values:
SELECT ‘A’ AS VALUE, ‘APPLE’ AS DESCR
UNION ALL
SELECT ‘B’, ‘BANANA’
UNION ALL
SELECT ‘C’, ‘CANTALOUPE’
UNION ALL
SELECT ‘D’, ‘DATE’
UNION ALL
SELECT ‘E’, ‘EGGPLANT’
The unknown values are dealt with by ignoring failures in the lookup, and setting the value in the derived column transform:
TRIM(LOOKUP_VALUE) == “” ? “UNKNOWN” : DESCRIPTION
I used 6 values (A, B, C, D, E, and an empty string) in the source. A, B, C, and D were each used in 20% of the source rows, and E and the empty string accounted for 10% of the source rows each.